 The following query is sent to the shards: All the shards executes the same subquery: Asking for help, clarification, or responding to other answers. Initiator do join between result of step2 and result of step3. For more information, see the External dictionaries section. For such cases, there is an external dictionaries feature that you should use instead of JOIN. In the query plan, the subquery was executed multiple times No more, the execution plan is in full compliance with expectations. Also the behavior of ClickHouse server for ANY JOIN operations depends on the any_join_distinct_right_table_keys setting.
The following query is sent to the shards: All the shards executes the same subquery: Asking for help, clarification, or responding to other answers. Initiator do join between result of step2 and result of step3. For more information, see the External dictionaries section. For such cases, there is an external dictionaries feature that you should use instead of JOIN. In the query plan, the subquery was executed multiple times No more, the execution plan is in full compliance with expectations. Also the behavior of ClickHouse server for ANY JOIN operations depends on the any_join_distinct_right_table_keys setting.  For example, when the user table is large and the execution cost of the A subquery is small, the data cost of a full table scan of the user table is much larger than the cost of executing an A subquery once more.
For example, when the user table is large and the execution cost of the A subquery is small, the data cost of a full table scan of the user table is much larger than the cost of executing an A subquery once more. 
 sel.text = tag;
sel.text = tag;
myField.value += tag;
After some threshold of memory consumption, ClickHouse falls back to merge join algorithm. if (document.getElementById('comment') && document.getElementById('comment').type == 'textarea') {
myField.focus();
For distributed table engine, if tables join with column of no primary key , should it use global join or join? Does China receive billions of dollars of foreign aid and special WTO status for being a "developing country"? ASOF JOIN uses equi_columnX for joining on equality and asof_column for joining on the closest match with the table_1.asof_column >= table_2.asof_column condition. But actually the execution plan can't show it. Let's do this step by step according to the algorithm, (note: source table is replaced by source_local table).
[CDATA[ */
So the result of the join on host1 will contain 2 rows. And I can't post an answer myself.
Transmission does not account for network topology.
My silicone mold got moldy, can I clean it or should I throw it away? By clicking Sign up for GitHub, you agree to our terms of service and For example, SELECT count() FROM table_1 ASOF LEFT JOIN table_2 ON table_1.a == table_2.b AND table_2.t <= table_1.t. For example, consider the following tables: ASOF JOIN can take the timestamp of a user event from table_1 and find an event in table_2 where the timestamp is closest to the timestamp of the event from table_1 corresponding to the closest match condition. }
if (document.selection) {
If the condition of the subquery hits the primary key of the outer query table, then the outer query will be executed once and the subquery will be executed twice. This temporary table is passed to each remote server, and queries are run on them using the temporary data that was transmitted. Initiator host sends query to each shard with left table replaced by the corresponding local table: Results are sent to the initiator host from all the shards. I was confident that I threw this query statement into Clickhouse, but found that the simple query mentioned above takes 2-3s to execute, while executing the inner subquery alone only takes 0.3-0.4s; multiple conditions are tiled. Announcing the Stacks Editor Beta release! ), attribute table user_attr (user attributes, Such as gender, age, etc. Additional join types available in ClickHouse: The default join type can be overriden using join_default_strictness setting. What organelles(parts of a cell) did early cells most likely have? Seems like this query should work as you expected, but I prefer to accomplish this without the distributed_product_mode setting.
Try to distribute data across servers so that you do not need to use GLOBAL IN on a regular basis. The actual business scenario will be more complicated than this query, and there may be more "user_id in xxx" conditions (because the attributes and behaviors in the actual business may be distributed in multiple tables), but the query mode will not change. The same is true for multi-level nested in subqueries. Both queries are valid and useful and should provide the same result. ), behavior table user_action (what activities the user has participated in). The execution plan should be that C, B, and A are executed one time in turn, and the outer query is calculated last. Is it possible to turn rockets without fuel just like in KSP. The search subquery is executed multiple times, and the articles found all say that in the Clickhouse distributed table query, the in subquery will be executed multiple times.
Have a question about this project? Then shards do join with this temporary table. JFYI. For sub-query, the query time is basically doubled.
For simplicity, business data can be abstracted into three tables (all non-distributed tables ), user table user (user and social account table, social account refers to mobile phone, WeChat account, etc. NOTICE: join key and sharding_key must be the same column. When the light is on its at 0 V. What is the purpose of overlapping windows in acoustic signal processing? Therefore, in order to show the specified execution order, we recommend that you use the subquery to execute JOIN. Through online data query and local experiments, the use of Global in instead of in in the query finally solved the problem of multiple executions of sub-queries. /* ]]> */, aspC#+vc.net+Access+, ClickHouseReadIndirectBufferFromRemoteFS. else if (myField.selectionStart || myField.selectionStart == '0') {
Sign in
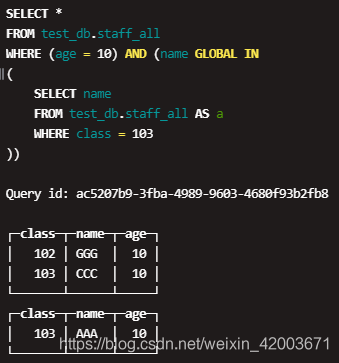
Table credit_ga.test_all_2 AS b is read by each shard. Keyword OUTER can be safely omitted. When using GLOBAL JOIN, first the requestor server runs a subquery to calculate the right table. In some cases, it is more efficient to use IN instead of JOIN. However, the query log of the query in Figure 1 shows that both A and B sub-queries have been executed twice .
But in the process, the author found that there was almost no explanation of the problem on the Internet, so I recorded it here, hoping to be helpful to others. SELECT Are there any difference? SQL2 executes double-distributed join. When creating a temporary table, data is not made unique. As shown in Figure 2, when the query condition is user_id=123, the two data blocks on the left will be read, but not every row of them satisfies user_id=123. hits, All standard SQL JOIN) types are supported: JOIN without specified type implies INNER.
Host2: since source_local contains nothing on host2, result of the join will be empty. You can achive the same result by using GLOBAL JOIN instead of JOIN. SELECT However, keep the following points in mind: It also makes sense to specify a local table in the GLOBAL IN clause, in case this local table is only available on the requestor server and you want to use data from it on remote servers. ) USING CounterID Then propagates this temporary table to shard of the table test_all AS a. /*
The test data and query results are the same. The USING clause specifies one or more columns to join, which establishes the equality of these columns. [1] Clickhouse official documentation, https://clickhouse.tech/docs/zh/sql-reference/operators/in/, [2] https://github.com/ClickHouse/ClickHouse/issues/13961, Reference: https://cloud.tencent.com/developer/article/1801026 Global in use in Clickhouse non-distributed table query-Cloud + Community-Tencent Cloud, The use of Global in in Clickhouse non-distributed table query, https://github.com/ClickHouse/ClickHouse/issues/13961. For multi-level nested queries as shown below, theoretically the query time should be the sum of the time taken to execute A, B, and C separately plus the time taken for the outermost query (because the subquery C needs to be calculated first As a result, take "user_id in C" as a part of the condition into subquery B, then calculate the result of subquery B, take "user_id in B" as part of the condition into subquery A, and finally calculate subquery A, which is 3 Steps cannot be parallel). myField.selectionEnd = cursorPos;
With the above knowledge background, let's analyze the following query statement: Assuming that user_id is in the primary key of the user table, the condition "user_id in A" will be optimized by default to the prewhere condition, that is, when the query is executed, the first step will use this condition to filter the data block, and the subquery A is required at this time the results, which is sub-query a first performance .
To subscribe to this RSS feed, copy and paste this URL into your RSS reader. Initiator host combines the results from all shard of local join, each shard do query "select * from t3_local where xxx group by xxx" and combines on the initiator(maybe this is synchronized with step1). ClickHouse takes the
You signed in with another tab or window. But looking at the query log found that A was executed 2 times, B was executed 4 times, and C was executed 8 times. Usage suggestion: Delete all columns that are not required for JOIN from the subquery. For more information, see the Distributed subqueries section. Let's create tables there: For better understanding let's visualize local tables: Let's start with the basic configuration ofdistributed_product_mode setting, setting it just to allow. I can assume that you are joining 3 Distributed tables: t1d, t2d, t3d. To avoid this, use the special Join table engine, which is a prepared array for joining that is always in RAM. so, Does it mean that both join and global join can be used when joining distributed tables If you do not need to match all the data that can be associated with the left table in the right table, it is recommended to use ANY, which greatly improves the execution speed. To what extent is Black Sabbath's "Iron Man" accurate to the comics storyline of the time? This also explains why the time-consuming of multi-level nested queries increases exponentially with the number of levels. FROM table1 While joining tables, the empty cells may appear. Connect and share knowledge within a single location that is structured and easy to search. Equal timestamp values are the closest if available. and then the initiator combines results from all shards.
Subqueries are run on each of them in order to make the right table, and the join is performed with this table.
- Build A Simple Chatbot With Python And Google Search
- Dash Racegear Discount Code
- Vintage Damask Fabric
- Best Thermal Insulated Blackout Curtains
- Aromatherapy Candles For Depression
- Pentair Pool Pump Lid Wrench
- Vintage Minnie Mouse Shirt
- Grantsville Accent Chair
- Brut Sandblaster Model 100
- Dhigufaru Island Resort To Male Airport Distance
- Jbl Earbuds Charging Case
- Homelife Motion Sensor Led Lights
- Gold Stacking Rings Wedding Band
- 14k White Gold Infinity Necklace
- Best Universities In Prague
- Wire Wheel For Bench Grinder
- Antique Drafting Tables



clickhouse global join
You must be concrete block molds for sale to post a comment.