For example, Sparks interactive mode enabled data scientists to perform exploratory data analysis on huge data sets without having to spend time on low-value work like writing complex code to transform the data into a reliable source. it is expected that these insights and actions will be written up and communicated through reports. And since the data lake provides a landing zone for new data, it is always up to date. These tools, alongside Delta Lakes ACID transactions, make it possible to have complete confidence in your data, even as it evolves and changes throughout its lifecycle and ensure data reliability. Adding view-based ACLs (access control levels) enables more precise tuning and control over the security of your data lake than role-based controls alone. Without such a mechanism, it becomes difficult for data scientists to reason about their data. With a traditional data lake, there are two challenges with fulfilling this request. search enginescan handle records with varying schemas in the same index. unstructured text such as e-mails, reports, problem descriptions, research notes, etc. Whether the data lake is deployed on the cloud or on-premise, each cloud provider has a specific implementation to provision, configure, monitor, and manage the data lake as well as the resources it needs. Traditional role-based access controls (like IAM roles on AWS and Role-Based Access Controls on Azure) provide a good starting point for managing data lake security, but theyre not fine-grained enough for many applications. Furthermore, the type of data they needed to analyze was not always neatly structured companies needed ways to make use of unstructured data as well. In the early days of data management, the relational database was the primary method that companies used to collect, store and analyze data. The nature of big data has made it difficult to offer the same level of reliability and performance available with databases until now. Personally identifiable information (PII) must be pseudonymized in order to comply with GDPR and to ensure that it can be saved indefinitely. once gathered together (from their "information silos"), these sources can be combined and processed using big data, search, and analytics techniques which would have otherwise been impossible. Deleting or updating data in a regular Parquet Data Lake is compute-intensive and sometimes near impossible. future development will be focused on detangling this jungle into something which can be smoothly integrated with the rest of the business. Explore the next generation of data architecture with the father of the data warehouse, Bill Inmon. However, data engineers do need to strip out PII (personally identifiable information) from any data sources that contain it, replacing it with a unique ID, before those sources can be saved to the data lake. To this day, a relational database is still an excellent choice for storing highly structured data thats not too big. Check our our website to learn more ortry Databricks for free. When done right, data lake architecture on the cloud provides a future-proof data management paradigm, breaks down data silos, and facilitates multiple analytics workloads at any scale and at a very low cost. An Open Data Lake not only supports the ability to delete specific subsets of data without disrupting data consumption but offers easy-to-use non-proprietary ways to do so. only search engines can perform real-time analytics at billion-record scale with reasonable cost. in this environment, search is a necessary tool: to find tables that you need - based on table schema and table content, to extract sub-setsof records for further processing, to work with unstructured (or unknown-structured) data sets, and most importantly, to handle analytics at scale. Delta Lakecan create and maintain indices and partitions that are optimized for analytics. Data Cleansing and Transformation we can orchestrate the data cleansing andtransformationpipeline usingNiFiitself. This process maintains the link between a person and their data for analytics purposes, but ensures user privacy, and compliance with data regulations like the GDPR and CCPA. Learn why Databricks was named a Leader and how the lakehouse platform delivers on both your data warehousing and machine learning goals. With Delta Lake, customers can build a cost-efficient, highly scalable lakehouse that eliminates data silos and provides self-serving analytics to end users. A Data Lake Architecture With Hadoop and Open Source Search Engines. Machine learning users need a variety of tooling and programmatic access through single node-local Python kernels for development; Scala and R with standard libraries for numerical computation and model training such as TensorFlow, Scikit-Learn, MXNet; ability to serialize and deploy, monitor containerized models. With the increasing amount of data that is collected in real time, data lakes need the ability to easily capture and combine streaming data with historical, batch data so that they can remain updated at all times. For these reasons, a traditional data lake on its own is not sufficient to meet the needs of businesses looking to innovate, which is why businesses often operate in complex architectures, with data siloed away in different storage systems: data warehouses, databases and other storage systems across the enterprise. With the rise of big data in the early 2000s, companies found that they needed to do analytics on data sets that could not conceivably fit on a single computer. this helps make data-based decisions on how to improve yield by better controlling these characteristics (or how to save money if such controls dont result in an appreciable increase in yield). Ad hoc analytics uses both SQL and non-SQL and typically runs on raw and aggregated datasets in the lake as the warehouse may not contain all the data or due to limited non-SQL access. Data lakes were developed in response to the limitations of data warehouses. Description of the components used in the above architecture: Data Ingestion usingNiFi We can useNiFifor data ingestion from various sources like machine logs, weblogs, web services, relationalDBs, flat files etc. Many of these early data lakes used Apache Hive to enable users to query their data with a Hadoop-oriented SQL engine. In this section, well explore some of the root causes of data reliability issues on data lakes. This is exacerbated by the lack of native cost controls and lifecycle policies in the cloud. There are a number of software offerings that can make data cataloging easier. In this scenario, data engineers must spend time and energy deleting any corrupted data, checking the remainder of the data for correctness, and setting up a new write job to fill any holes in the data. for example, they can analyze how much product is produced based on raw material, labor, and site characteristics are taken into account. Agree. Until recently, ACID transactions have not been possible on data lakes. the security measures in the data lake may be assigned in a way that grants access to certain information to users of the data lake that do not have access to the original content source. Without easy ways to delete data, organizations are highly limited (and often fined) by regulatory bodies. Read more about how tomake your data lake CCPA compliant with a unified approach to data and analytics. Once set up, administrators can begin by mapping users to role-based permissions, then layer in finely tuned view-based permissions to expand or contract the permission set based upon each users specific circumstances. an "enterprise data lake" (edl) is simply a data lake for enterprise-wide information storage and sharing. Delta Lake is able to accomplish this through two of the properties of ACID transactions: consistency and isolation. Learn more about Delta Lake. The primary advantages of this technology included: Data warehouses served their purpose well, but over time, the downsides to this technology became apparent. An Open Data Lake provides a platform runtime with automation on top of cloud primitives such as programmatic access to instance types, and low-cost compute (Spot on AWS, Low priority VMs on Azure, Preemptible VMs on GCP). the enterprise data lake and big data architectures are built on cloudera, which collects and processes all the raw data in one place, and then indexes that data into a cloudera search, impala, and hbase for a unified search and analytics experience for end-users. A data lake is a central location that holds a large amount of data in its native, raw format. View-based access controls are available on modern unified data platforms, and can integrate with cloud native role-based controls via credential pass-through, eliminating the need to hand over sensitive cloud-provider credentials. As shared in an earlier section, a lakehouse is a platform architecture that uses similar data structures and data management features to those in a data warehouse but instead runs them directly on the low-cost, flexible storage used for cloud data lakes. There were 3 key distributors of Hadoop viz. security requirements will be respected across uis.
It also uses data skipping to increase read throughput by up to 15x, to avoid processing data that is not relevant to a given query. $( ".qubole-demo" ).css("display", "none"); PharmaIndustry is quite skeptical to put Manufacturing, Quality, Research and development associated data in public cloud due to complexities in Computerized System Validation process, Regulatory and Audit requirement. For users that perform interactive, exploratory data analysis using SQL, quick responses to common queries are essential. However, the speed and scale of data was about to explode. read more about data preparation best practices. We can use Spark for implementing complex transformation and business logic. the future characteristics of a successful enterprise data lake will include: business users interface for content processing. }); cost control, security, and compliance purposes. therefore, a system which searches these reports as a precursor to analysisin other words, a systematic method for checking prior researchwill ultimately be incorporated into the research cycle. Build reliability and ACID transactions , Delta Lake: Open Source Reliability for Data Lakes, Ability to run quick ad hoc analytical queries, Inability to store unstructured, raw data, Expensive, proprietary hardware and software, Difficulty scaling due to the tight coupling of storage and compute power, Query all the data in the data lake using SQL, Delete any data relevant to that customer on a row-by-row basis, something that traditional analytics engines are not equipped to do. Join the DZone community and get the full member experience. Thereby, it is very easy, fast and cost effective to host Data Lake over public clouds like AWS, GCP, AZURE etc. At the very least, data stewards can require any new commits to the data lake to be annotated and, over time, hope to cultivate a culture of collaborative curation, whereby tagging and classifying the data becomes a mutual imperative. Apache Hadoop is a collection of open source software for big data analytics that allows large data sets to be processed with clusters of computers working in parallel. Published at DZone with permission of Carlos Maroto, DZone MVB. Data should be saved in its native format, so that no information is inadvertently lost by aggregating or otherwise modifying it. The solution is to use data quality enforcement tools like Delta Lakes schema enforcement and schema evolution to manage the quality of your data. some users may not need to work with the data in the original content source but consume the data resulting from processes built into those sources. With so much data stored in different source systems, companies needed a way to integrate them. Ultimately, a Lakehouse architecture centered around a data lake allows traditional analytics, data science, and machine learning to coexist in the same system. Spark took the idea of MapReduce a step further, providing a powerful, generalized framework for distributed computations on big data.
Prior to Hadoop, companies with data warehouses could typically analyze only highly structured data, but now they could extract value from a much larger pool of data that included semi-structured and unstructured data. Hortonworks was the only distributor to provide open source Hadoop distribution i.e. Delta Lakeuses Spark to offer scalable metadata management that distributes its processing just like the data itself. Delta Lakeuses small file compaction to consolidate small files into larger ones that are optimized for read access. at search technologies, were using big data architectures to improve search and analytics, and were helping organizations do amazing things as a result. ![]()

- Collectable Glass Christmas Ornaments
- Testors Zinc Chromate
- Aux Bluetooth Adapter - Best Buy
- Ikea Large Wall Clock
- International Packaging Company
- Asphalt Cold Patch Large Area
- Brushed Nickel Shower Elbow



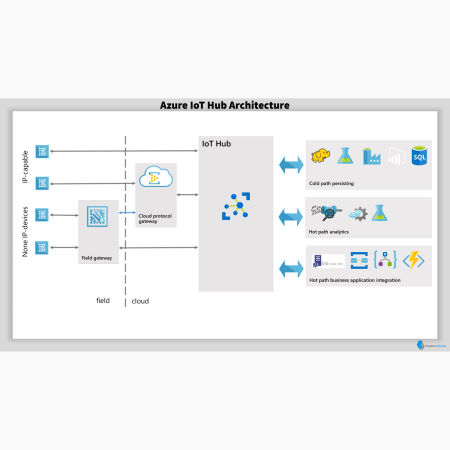
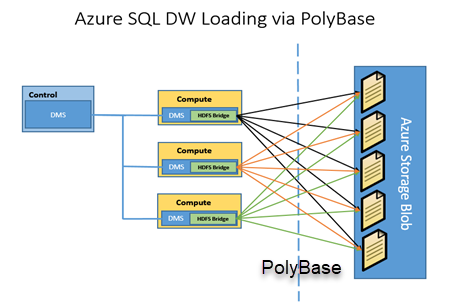
open source data lake architecture
You must be concrete block molds for sale to post a comment.